Die Syntax von HTML ist kompliziert – viel komplizierter, als die meisten Autoren ahnen. So ist
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN">
<>
<title//
<p ltr<span></span</p>
</>gültiges HTML und zu
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html>
<head>
<title></title>
<body>
<p dir="ltr"><span></span></p>
</body>
</html>äquivalent. Die meisten Benutzeragenten (dazu gehören Browser oder die Crawler von Suchmaschinen) können die minimierte Version nicht korrekt verarbeiten, und doch zeigt der W3C-Validator bestenfalls Warnungen, aber keine Fehler an.
Verantwortlich dafür sind einige
SGML-Features in HTML. Kaum ein Autor verwendet diese Features absichtlich. Es kann aber passieren, daß man versehentlich ein
> vergißt. Darstellungsprobleme sind dann sehr schwer aufzuspüren, denn das Dokument entspricht ja der Spezifikation, und ein Validator findet deshalb keine Fehler. Tatsächlich kann XHTML, das den
Kompatibilitätsrichtlinien genügt, besser von heutigen HTML-Benutzeragenten verarbeitet werden als gültiges HTML, das – egal ob vom Autor beabsichtigt oder nicht – diese SGML-Features verwendet.
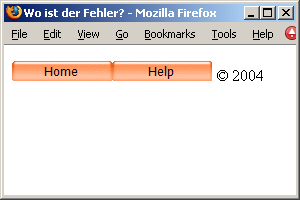
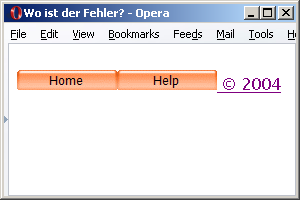
Sehen Sie in
<p><a href="http://www.example.org/"><img border="0" src="../button1.gif" height="20" width="100" alt="Home"></a><a href="http://www.example.org/"><img border="0" src="../button2.gif" height="20" width="100" alt="Help"</a> © 2004</p>
auf Anhieb das Problem? IE, Firefox und Opera sind sich nicht einig, wie dieses Dokument angezeigt werden sollte. Der W3C-Validator hat nichts zu beanstanden, nicht einmal der Parse-Baum zeigt Auffälligkeiten. In einem vergleichbaren XHTML-Dokument wird der Fehler hingegen sofort aufgespürt.
Außerdem können in HTML viele Elemente implizit geöffnet oder geschlossen werden. Das führt häufig zu verwirrenden Fehlermeldungen bei der Validierung. Aber auch in einem gültigen Dokument kann das Weglassen eines schließenden Tags wie
</td> problematisch sein. Wiederum spielt es keine Rolle, ob der Autor das absichtlich oder versehentlich getan hat – Netscape 4.x reagiert darauf sehr allergisch.
Schließlich ist HTML in hohem Maße kontextabhängig.
<a href=foo.html>,
<p>x < y</p> und
<p>ü</p> sind gültige Fragmente,
<a href=../foo.html>,
<p>x<y</p> und
<p>Tür</p> nicht. Auch kleine Änderungen können also ein gültiges Dokument ungültig machen.
An der Rechtschreibreform hat Bernhard Eversberg sehr treffend die Beliebigkeit als größtes Problem erkannt. Für HTML gilt dasselbe:
<div><p></div> ist korrekt,
<div><p></p></div> aber auch.
<p dir="LTR"> ist korrekt,
<p dir="ltr"> aber auch.
<style type="text/css"><!-- /* ... */ --></style> ist korrekt,
<style type="text/css">/* ... */</style> aber auch.
<p>ä</p> ist korrekt,
<p>ä</p> aber auch.
<a href=foo.html> ist korrekt,
<a href="foo.html"> aber auch.
In XHTML gibt es in all diesen Fällen eine korrekte Schreibweise. Und das ist nicht die einzige Gemeinsamkeit von HTML und reformierter Rechtschreibung. Beide wollen das Schreiben einfacher machen und nehmen dafür in Kauf, daß das Lesen schwieriger wird.
Durch strengere DTDs und SGML-Deklarationen könnte der W3C-Validator zwar viel mehr Fehler in HTML-Dokumenten aufspüren, aber die offensichtlichen Tippfehler in
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html>
<head><title>...</title></head>
<body>
<p title=""style=""></p>
<p> < & > </p>
<p>ä</p>
<!------><hr><!------>
</body>
</html>können von einem SGML-Parser prinzipiell nicht gefunden werden. Tagsoup-Parser könnten sie aber durchaus irritieren. XHTML vermeidet all diese Probleme. Die Syntax ist einfacher, intuitiver und damit nicht nur für Anfänger viel besser geeignet.
In Zweifelsfällen ist es zudem von Vorteil, daß die XML-Spezifikation für jeden kostenlos im Netz abrufbar ist. Wer hingegen die SGML-Spezifikation lesen will, muß dafür bezahlen.
Ein weiterer Vorteil ist die bessere Validierbarkeit von XHTML mittels Schemata. Der W3C-Validator gilt zwar gemeinhin als überaus streng, er
kann viele Fehler aber überhaupt nicht finden;
<html lang="klingon"> geht bspw. als gültiges HTML-Fragement durch. Ein
Schema-Validator hingegen kann feststellen, wenn ein Attributwert ungültig ist.
Schließlich lassen sich bei XHTML XML-Tools einsetzen – XSLT und DOM funktionieren nämlich besser als das Herumgestochere im Quelltext mit regulären Ausdrücken.
document.write() kann
nicht mehr verwendet werden. Sonst fällt mir ehrlich nichts ein.
Einige Leuten meinen, XHTML sei besser als HTML für „moderne“, auf CSS basierende Layouts ohne Tabellen geeignet und habe Vorteile für die Barrierefreiheit. Das ist natürlich völliger Quatsch. HTML 4.01 und XHTML 1.0 unterscheiden sich lediglich syntaktisch. Die Verwendung von XHTML 1.1 ist sogar nachteilig für die Barrierefreiheit.
Microsoft hat es geschafft, fast alle unsinnigen Argumente für XHTML in einem einzigen Dokument zu nennen.
Manche Leute behaupten, IE unterstütze bspw.
<br /> nicht.
Angeblich existieren auch Benutzeragenten, die bspw.
<input type="checkbox" checked="checked" /> nicht verstehen, sondern nur die minimierte Form
<input type="checkbox" checked />. Ich habe solche Benutzeragenten noch nicht gesehen. HTML erlaubt ja auch beide Varianten, d.h. HTML-Benutzeragenten müssen mit beiden Varianten umgehen können.
Es gibt in der Tat Benutzeragenten, die die o.g. SGML-Features korrekt interpretieren, bspw. Emacs/W3. Diese Benutzeragenten können XHTML-Dokumente in der Tat nicht verarbeiten, auch wenn sie den Kompatibilitätsrichtlinien entsprechen. Diese Benutzeragenten können aber auch die meisten der heute im Web publizierten HTML-Dokumente nicht sinnvoll verarbeiten.
Viele Autoren wollen keine XML-Deklaration verwenden, weil diese verhindert, daß IE in den
standards compliant mode schaltet. Eine XML-Deklaration ist aber nur dann erforderlich, wenn das XHTML-Dokument nicht UTF-8- oder UTF-16-codiert ist
und der HTTP-
Content-Type-Header keinen
charset-Parameter enthält. Beachten Sie einfach die Hinweise zur Deklaration der
Zeichencodierung.
Kritiker von XHTML verweisen gern auf den Artikel Sending XHTML as text/html Considered Harmful von Ian Hickson. Leider ist dieser Artikel einseitig, irreführend und teilweise auch schlichtweg falsch:
<script> and <style> elements in XHTML sent as text/html have to be escaped using ridiculously complicated strings.
In der Tat möchte man Konstruktionen wie
<script type="text/javascript"><!--//--><![CDATA[//><!--
...
//--><!]]></script>oder
<style type="text/css"><!--/*--><![CDATA[/*><!--*/
...
/*]]>*/--></style>nicht ernsthaft verwenden. Muß man ja auch nicht – das Einbetten von JavaScript- oder CSS-Code in XHTML ist kaum schwieriger als in HTML.
IE6 does not support application/xhtml+xml (in fact, it does not support XHTML at all).
Das stimmt natürlich, jedoch impliziert die Darstellung, IE6 unterstütze HTML. Das tut er aber noch viel weniger.
Using XHTML and sending it as text/html is effectively the same, from an HTML4 point of view, as writing tag soup.
Dieselbe Taktik. Erstens bestreitet das niemand, und zweitens ist auch HTML, das als
text/html ausgeliefert wird, für den typischen Benutzeragenten nur Tagsoup.
The "xmlns" attribute is invalid HTML4.
Dann wird es eben ignoriert, genau das empfiehlt die HTML-Spezifikation ja.
RFC 2854 spec refers to "a profile of use of XHTML which is compatible with HTML 4.01".
Dieser Satz steht leider wirklich in
RFC 2854, und Hickson stürzt sich natürlich sofort auf diese sprachliche Ungenauigkeit. Das Ziel der Kompatibilitätsrichtlinien
laut XHTML-1.0-Spezifikation ist aber nicht die Kompatibilität von XHTML und HTML, denn diese ist unbestreitbar nicht zu erreichen. Vielmehr sollen XHTML-Dokumente von
existing HTML user agents
verarbeitet werden kann. Das ist ein wesentlicher Unterschied. Es ist deshalb auch ganz einfach, die Tauglichkeit der Kompatibilitätsrichtlinien zu widerlegen: Man erstelle ein XHTML-1.0-Dokument, das den Kompatibilitätsrichtlinien genügt und von einem einigermaßen aktuellen Benutzeragenten (sagen wir, ab Netscape 3.x) anders dargestellt wird als das entsprechende HTML-Dokument. Bisher hat mir niemand ein solches XHTML-Dokument präsentieren können.
XHTML 1.0 verwendet praktisch dasselbe Vokabular wie HTML 4.01; XHTML 1.1 tut das nicht. Deshalb können XHTML-1.0-Dokumente von HTML-Benutzeragenten verarbeitet werden, wenn sie den Kompatibilitätsrichtlinien genügen, XHTML-1.1-Dokumente hingegen nicht. Das ist die Begründung dafür, daß XHTML-1.1-Dokumente nicht als
text/html deklariert werden
sollten.
In XHTML 1.1 fehlt das für die Zugänglichkeit wichtige
lang-Attribut. Es existieren Benutzeragenten, die das
lang-Attribut unterstützen, das
xml:lang-Attribut aber nicht, bspw. der IBM Home Page Reader.
Außerdem ist das
usemap-Attribut in XHTML 1.1 vom Typ
IDREF, so daß bislang benutzte Werte wie
#map ungültig werden; Werte wie
map können aber von vielen HTML-Benutzeragenten nicht verarbeitet werden.
text/html oder
application/xhtml+xml oder
application/xml oder
text/xml?
Internet Explorer und zahlreiche andere Benutzeragenten unterstützen den Inhaltstyp
application/xhtml+xml nicht oder können XHTML-Dokumente, die mit den Inhaltstypen
application/xml oder
text/xml ausgeliefert werden, nicht verarbeiten. (Den
Content-Type-Header können Sie bequem mit
Web-Sniffer einsehen.)
Die einfachste Lösung besteht darin, XHTML-Dokumente als
text/html auszuliefern. Dies ist für XHTML-1.0-Dokumente, die den Kompatibilitätsrichtlinien genügen,
zulässig und unproblematisch. Die Einhaltung der Kompatibilitätsrichtlinien sollten Sie stets
überprüfen.
Komplizierter wird es, wenn Sie mittels
Content Negotiation eine
text/html- und eine
application/xhtml-xml-Variante ausliefern wollen. Es existieren zwar Anleitungen für PHP, ASP.NET und Apache, die teilweise jedoch recht abenteuerlich sind. Manchmal wird nicht einmal der
Accept-, sondern der
User-Agent-Header ausgewertet!
Content Negotiation führt dazu, daß mit HTTP 1.0 Caching unmöglich wird.
Caching von verhandelbaren Ressourcen ist auf die Header
Vary,
ETag,
If-Match und
If-None-Match angewiesen, und die gibt es erst in HTTP 1.1. (Es geht hier überhaupt nicht um den
Host-Header; den schicken auch viele Benutzeragenten, die ansonsten nur HTTP 1.0 verstehen.) HTTP 1.0 ist keineswegs obsolet – standardmäßig ist im IE6
Extras Internetoptionen… Erweitert HTTP 1.1 über Proxyverbindungen verwenden deaktiviert. Praktisch läuft das darauf hinaus, daß man Caching mindestens in öffentlichen Caches unterbinden muß. Sie müssen sich darüber im klaren sein, daß eine fehlerhafte Konfiguration des Servers fatale Auswirkungen haben kann, etwa wenn IE eine
application/xhtml+xml-Ressource aus einem Cache erhält. Solche Fehler sind zudem nur sehr schwer aufzuspüren.
Die o.g.
Vorteile von XHTML gelten auch für
text/html-Ressourcen, so daß ich inzwischen von Content Negotiation abrate. Für Content Negotiation sprechen allerdings folgende Argumente:
text/html ausliefert, läuft Gefahr, Verstöße gegen Wohlgeformtheits-Bedingungen nicht sofort zu bemerken. Der W3C-Validator erkennt nicht alle Verstöße, denn er hat einige ärgerliche
Einschränkungen. Sie sollten also einen richtigen XML-Validator verwenden, bspw. meinen
Schema-Validator oder
Page Valet, wobei Sie Xerces manuell als Parser auswählen müssen. Testen Sie außerdem mit
XHTML Proxy!
application/xhtml+xml seinen
„full standards mode“ ein, ohne das konzeptionell untaugliche
DOCTYPE sniffing bemühen zu müssen.
Beim Einsatz von Content Negotiation können Sie anstelle von
application/xhtml+xml auch
application/xml ausliefern, XHTML-Benutzeragenten unterstützen beides. Hingegen sollte
text/xml
niemals benutzt werden, denn die Regeln zur Bestimmung der Zeichencodierung einer
text/xml-Ressource sind völlig
idiotisch. Ich kenne keinen Benutzeragenten, der
text/xml spezifikationskonform unterstützt, auch wenn bspw. Mozilla das mit seinem
Accept: text/xml glauben machen möchte.
Einige verwirrte Leute sind offenbar der Überzeugung, mit
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=utf-8" />
in einem
text/html-Dokument den XML-Parser des Benutzeragenten aktivieren zu können. Das ist natürlich Unsinn. Ein Benutzeragent müßte mit seinem Tagsoup-Parser beginnen und ab dem
meta-Element mit seinem XML-Parser weitermachen oder gar noch einmal von vorne beginnen.
Tatsächlich ist
application/xhtml+xml an dieser Stelle nicht nur wirkungslos, sondern sogar schädlich. Mindestens Lynx nämlich kann aus
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />die Deklaration der Codierung ermitteln, aus
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=iso-8859-1" />aber nicht. Es spricht nichts dagegen, auch in einem XHTML-Dokument die Zeichencodierung bspw. mit
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
anzugeben. Das kann sogar notwendig sein, wenn Sie die Zeichencodierung ansonsten nur in der XML-Deklaration angegeben und nicht in einem
„echten“ HTTP-Header wie
Content-Type: text/html; charset=iso-8859-1, denn HTML-Benutzeragenten verarbeiten die XML-Deklaration nicht.
Mit
application/xhtml+xml im richtigen
Content-Type-Header ist das
meta-Element hingegen völlig irrelevant.
Ich rate im allgemeinen vom Einsatz von Content Negotiation ab. Wenn Sie es trotzdem versuchen wollen, sind hier zwei Ansätze, die sich einigermaßen bewährt haben:
Apache verfügt mit seiner
Content Negotiation über einen leistungsfähigen Mechanismus, um Clients mit der für sie am besten geeigneten Variante einer Ressource zu beliefern. Varianten werden dabei normalerweise in verschiedenen Dateien gespeichert, so könnte bspw.
dokument.html die HTML-Repräsentation eines Dokuments enthalten,
dokument.pdf die Repräsentation im PDF-Format und schließlich
dokument.txt eine Repräsentation als
text/plain. Der Zugriff auf die Ressource erfolgt über die URL
dokument, Apache erledigt den Rest.
Es wäre wünschenswert, wenn dieser Mechanismus auch mehrere Varianten einer Repräsentation zuordnen könnte. Eine Datei, die ein XHTML-Dokument enthält, welches den
Kompatibilitätsrichtlinien entspricht, könnte dann als
text/html
und
application/xhtml+xml ausgeliefert werden. Diese Möglichkeit besteht nach meinen Erfahrungen aber nicht. Sie müssen daher Ihre Dokumente doppelt auf dem Server ablegen.
Nennen Sie bspw. eine Kopie
dokument.html und die zweite
dokument.xhtml. Ergänzen Sie die
.htaccess dann um folgende Direktiven:
Options +MultiViews
AddType text/html;charset=iso-8859-1 .html
AddType application/xhtml+xml;charset=iso-8859-1;qs=0.999 .xhtmlGgf. müssen Sie eine andere Codierung angeben.
Die
qs-Werte verdienen besondere Beachtung. Der HTML-Variante wird eine geringfügig höhere Qualität zugewiesen. Der IE, der einfach nur
*/* verlangt, erhält deshalb diese Variante. Opera ist unproblematisch, da er
text/html explizit angibt. Mozilla wertet in seinem
Accept-Header die XHTML-Variante (1.0) entschieden höher als die HTML-Variante (0.9). Der vom Apache verwendete
Algorithmus wird deshalb für Mozilla die XHTML-Variante selektieren.
Wenn Sie auf Ihrem Webserver Skripte ausführen können oder sogar Shell-Zugang haben, können Sie Kopien vermeiden, indem Sie symbolische Links erstellen.
Der
qs-Parameter in der
AddType-Direktive beeinflußt leider nicht nur die Auswahl der Variante; er erscheint auch im
Content-Type-Header.
RFC 3236 erlaubt für den MIME-Typ
application/xhtml+xml aber nur die Parameter
charset und
profile, eine Ausgabe wie
Content-Type: application/xhtml+xml; charset=iso-8859-1; qs=0.999 ist also nicht RFC-konform. Mir ist allerdings kein Benutzeragent bekannt, der sich daran stört.
Bei Verwendung von Type-Maps wird der
qs-Parameter nicht in den
Content-Type-Header geschrieben. Pro Ressource müssen dann allerdings
drei Dateien gespeichert werden. Ein
Perl-Script von Henri Sivonen leistet hier sicherlich gute Dienste. Es erzeugt für alle
.xml-Dateien symbolische Links als
.html und generiert eine
.var-Datei.
Mit
mod_rewrite läßt sich eine einfache, aber nicht ganz saubere Lösung konstruieren. Sie müssen Ihre Dokumente oder deren Dateinamen nicht ändern, sondern einfach nur einige Direktiven in die
.htaccess aufnehmen:
RewriteEngine On
RewriteCond %{HTTP_ACCEPT} application/xhtml\+xml
RewriteCond %{HTTP_ACCEPT} !application/xhtml\+xml\s*;\s*q=0
RewriteCond %{REQUEST_URI} \.html$
RewriteCond %{THE_REQUEST} HTTP/1\.1
RewriteRule .* - "[T=application/xhtml+xml; charset=iso-8859-1]"Achten Sie auch hier wieder auf die richtige Codierung!
Apache ändert dann den Inhaltstyp aller Dateien mit der Endung
.html vom voreingestellten
text/html in
application/xhtml+xml, wenn der
Accept-Header des Browsers diese Zeichenfolge enthält, der zugehörige
q-Wert nicht mit einer Null beginnt und die Anfrage mittels HTTP 1.1 gestellt wird. Unter Apache 1.x funktioniert das auch für Standarddokumente, die per
/ angefordert werden, nicht aber unter Apache 2.x.
Apache erzeugt einen korrekten
Vary-Header, wenn der Inhaltstyp verändert wird, so daß HTTP-1.1-Clients die Ressource cachen können. HTTP-1.0-Clients kennen den
Vary-Header aber nicht. Um Caching-Probleme zu vermeiden, wird ihnen eine Antwort mit dem originalen Inhaltstyp geschickt.
Google hilft.
Sie können leicht mit einem Telnet-Client testen, ob die Konfiguration wie gewünscht funktioniert. Stellen Sie dazu mittels
telnet www.example.org 80 eine Verbindung zum Webserver her und geben Sie dann folgendes ein:
HEAD / HTTP/1.1
Host: www.example.org
Accept: application/xhtml+xml
Connection: closeDer Server sollte dann etwa so antworten:
HTTP/1.1 200 OK
Vary: Accept
Content-Type: application/xhtml+xml; charset=iso-8859-1
Entscheidend ist der
Content-Type-Header. Enthält er
application/xhtml+xml und eine Zeichencodierungsdeklaration, ist alles in Ordnung.
Die Kompatibilitätsrichtlinien empfehlen, JavaScript- und CSS-Code als externe Ressourcen abzulegen, wenn im Quelltext bestimmte Zeichenfolgen auftreten. Das ist natürlich möglich, ist aber nicht erforderlich. Man kann JavaScript- und CSS-Code stets so in XHTML-Dokumente einbinden, daß sowohl HTML- als auch XHTML-Benutzeragenten den Code korrekt interpretieren.
Die Elementtypen
script und
style sind in HTML mit CDATA-Inhaltsmodell definiert. Das heißt, daß Zeichen wie
< oder
& automatisch
„entwertet“ sind;
< leitet in einem HTML-
script-Element also
kein
Tag ein und
&
keine
Entity-Referenz.
In XML gibt es das CDATA-Inhaltsmodell nicht mehr. Stattdessen gibt es
CDATA-Abschnitte. Ohne explizit notierten CDATA-Abschnitt verhalten sich die Zeichen
< oder
& in einem XHTML-
script-Element also genauso wie etwa in einem
p-Element, d.h. sie leiten ein
Tag bzw. eine
Entity-Referenz ein.
Es ergibt sich also das Problem, daß
<script type='text/javascript'>alert('AC;')</script> in einem HTML-Dokument eine andere Bedeutung hat als in einem XHTML-Dokument – ein HTML-Benutzeragent würde
AC; anzeigen, ein XHTML-Benutzeragent hingegen
€.
In dieser Hinsicht
„gefährlich“ sind die Zeichenfolgen
< und
&. Wenn diese Zeichenfolgen im JavaScript- oder CSS-Code auftreten, betten Sie den Code folgendermaßen ein:
<script type='text/javascript'>
/* <![CDATA[ */
s = '<';
/* ]]> */
</script>
<style type='text/css'>
/* <![CDATA[ */
p:after { content: '&'; }
/* ]]> */
</style>
Der CDATA-Abschnitt sorgt dafür, daß sich XHTML-Benutzeragenten den Inhalt der Elemente so lesen wie HTML-Benutzeragenten. Die Kommentare
/* */ wiederum sorgen dafür, daß in HTML-Benutzeragenten die CDATA-Marken nicht als JavaScript- oder CSS-Code intepretiert werden.
JavaScript- oder CSS-Code, der die o.g. Zeichenfolgen nicht enthält, kann auch sicher ohne CDATA-Abschnitt eingebettet werden:
<script type='text/javascript'>
s = '>';
</script>
<style type='text/css'>
p:after { content: '+'; }
</style>
Auf keinen Fall dürfen Kommentare (<!-- -->) verwendet werden, um den Inhalt von
style- und
script-Elementen vor älteren Benutzeragenten zu verstecken, denn XML-Parser dürfen Kommentare einfach ignorieren.
Problematisch ist lediglich die Zeichenfolge
]]>, die ja das Ende eines CDATA-Abschnitts markiert. In XML darf sie nicht anderweitig benutzt werden, bspw.
<p>]]></p> ist nicht wohlgeformt. Wenn Sie diese Zeichenfolge in JavaScript- oder CSS-Code benötigen, müssen Sie sie zerlegen, bspw. so:
<style type="text/css">
p:after { content: "]]" ">"; }
</style>
<script type="text/javascript">
alert(']]'+'>');
</script>
Die Entity-Referenzen
<,
>,
" und
& sind in XHTML völlig unproblematisch. Vermeiden sollte man
', weil HTML-Benutzeragenten damit nichts anfangen können, und den ganzen Rest wie
ä oder
, denn diese sind in der DTD deklariert. Bei HTML-Benutzeragenten spielt das keine Rolle; XHTML- und XML-Benutzeragenten können diese Entity-Referenzen jedoch nur auflösen, wenn sie Zugriff auf die DTD haben und einen validierenden Parser verwenden. Mozilla etwa verwendet im Gegensatz zu IE keinen validierenden Parser und kann Entity-Referenzen im allgemeinen nicht auflösen, es funktioniert aber
ausnahmsweise mit einigen Dokumenttyp-Deklarationen.
Mit UTF-8 kann man auf Entity-Referenzen leicht verzichten, ansonsten nimmt man eben numerische Zeichenreferenzen wie
ä. (Die hexadezimale Schreibweise
ä wird von einigen Netscape-4.x-Versionen nicht unterstützt und sollte deshalb vermieden werden.)
Es ist nicht ganz einfach, die Codierung eines XHTML-Dokuments, das als
text/html ausgeliefert wird, so zu deklarieren, daß sowohl HTML-Benutzeragenten als auch XML-Software das Dokument decodieren können. Dabei sind folgende Bedingungen zu berücksichtigen:
meta-Element. (Das
meta-Element wird von einigen Benutzeragenten ignoriert, wenn es erst spät auftaucht. Deshalb sollte das
meta-Element immer das erste Kind des
head-Elements sein.)
meta-Element ignorieren. (Das ist übrigens kein Rückschritt gegenüber HTML, sondern die Voraussetzung für einfache und schnelle Parser, denn man
erspart sich so, das Dokument zu decodieren, um herauszufinden, wie man es decodieren muß.)
Daraus folgt inbesondere:
Content-Type-Header deklarieren. Ein
meta-Element
genügt nicht. (Der W3C-Validator und Validome sehen das dummerweise anders.)
meta-Element zu deklarieren.
<,
>,
" und
&.
text/html aus. Content Negotiation lohnt sich nicht.
{kind=link}
{kind=link}
{kind=link}